O termo trabalho é originário do latim tripalium, que designa instrumento de tortura.
Resultados do Google, 2021.
Saudações a todos! Este é o primeiro post do blog em que eu trabalho montando e explicando um código em R (confesso que estou meio sem ideias ultimamente, muita coisa acontecendo). Sendo assim, aqui eu mostro como ler os arquivos do CAGED (Cadastro Geral de Empregados e Desempregados) de forma eficiente para você, que não tem um notebook com SSD e/ou 16 Giga de memória RAM, assim como eu (sad reactions only).
Antes de tudo, você vai precisar baixar os arquivos “.zip” e extraí-los, o download pode ser feito neste endereço de FTP aqui. Crie uma pasta em seu diretório chamada “caged” (eu fiz assim, but copia se quiser). Feito isso, informe no seu script o local onde esses arquivos estão com os seguintes comandos:
require(tidyverse)
require(magrittr)
paste0("~/caged/", dir("~/caged")) ## checando locais
Dessa forma você já vai poder checar o local onde os arquivos estão. Também é importante baixar o dicionário de dados que está disponível aqui (o arquivo mais bem formatado que já vi em toda minha existência).
Agora vem o segredo do mágico, a carta na manga, o coelho da cartola, o coringa do jogo… ok, já chega. Depois de tudo pronto, agora é preciso ler os arquivos e “guardá-los” em uma lista. A ideia é a seguinte: são onze arquivos, um para cada mês. Sendo assim, é necessário empilhar todos eles em sequência. Porém, há um problema, depois dos dados descompactados, o tamanho dessa database fica próximo de 3 Gigabytes. Então se você tem um computador “pela hora da morte” assim como eu, é interessante que filtre as informações mais relevantes. Neste exemplo, vamos trabalhar apenas com o estado do Maranhão.
lista_arquivos <- paste0("~/caged/", dir("~/caged")) %>%
lapply(function(y){readr::read_delim_chunked(y, delim = ";",
DataFrameCallback$new(function(x, pos){
subset(x, uf == "21")}))})A função read_delim_chunked do pacote readr faz dois serviços simultâneos que são bem úteis neste tipo de extração. O primeiro é um teste lógico sobre cada coluna, diminuindo o ruído causado por má especificação da class nas colunas (evita que os dados sejam empilhados com erros) e o segundo serviço é feito pelo argumento “callback”: inserindo a função DataFrameCallback é possível filtrar, durante a leitura, somente as observações de interesse. Todo processo pode ser entendido como uma leitura por blocos (chunks). “21” é o código do estado do Maranhão na coluna “uf”.
Para finalizar, agora resta apenas fazer o empilhamento da base com a função “rbindlist” do velozíssimo pacote “data.table”:
caged <- data.table::rbindlist(lista_arquivos)
caged %<>%
mutate(date = as.Date(
str_c(2020,
str_sub(competência, start = -2),
01, sep = "-")
)
)
E voilá os dados foram extraídos e estão prontos para uso. Em seguida, é interessante criar uma coluna de datas a partir da coluna “competência”.
Hm, interessante, e se ao invés de trabalhar com códigos, fosse interessante atribuir os “labels” originais à essa base?
Muito simples, basta usar as tabelas auxiliares do dicionário. Criaremos uma função capaz de identificar o código presente em uma determinada coluna e vinculá-lo a um determinado campo com o respectivo “label”.
Ex: busque o código “21” na coluna “uf” e retorne o label “Maranhão” na coluna “Descrição” na tabela “uf” do dicionário (Literalmente, é isso que a função faz).
O dicionário baixado anteriormente é composto por várias tabelas auxiliares, para facilitar, vocês podem ler todas elas simultaneamente usando a função “import_list” do pacote “rio”.
tabela_auxiliares <- rio::import_list("CAGED/Layout Novo Caged Movimentação.xlsx")
final_label <- function(nome, tabela = caged){
sapply(get(nome, tabela),
function(x){
number <- which(x == tabela_auxiliares[[nome]][[1]])
return(tabela_auxiliares[[nome]][[number, 2]])
}
)
}A forma de uso é muito simples: escolha uma coluna para alterar e informe novamente dentro da função o nome dessa coluna. A seguir vai um exemplo com as primeiras seis linhas do arquivo, vamos reconhecer o código da ocupação do trabalhador (CBO 2002)
teste <- head(caged)
teste %>%
mutate(cbo2002ocupação = final_label("cbo2002ocupação")) %>%
View
Pronto, é possível ver que a coluna “cbo2002ocupação” foi recriada conforme as informações disponíveis no dicionário de dados
Agora vamos brincar um pouco, quais temas podem ser visualizados a partir dessa base? Separei dois recortes bem interessantes para mostrar aqui:
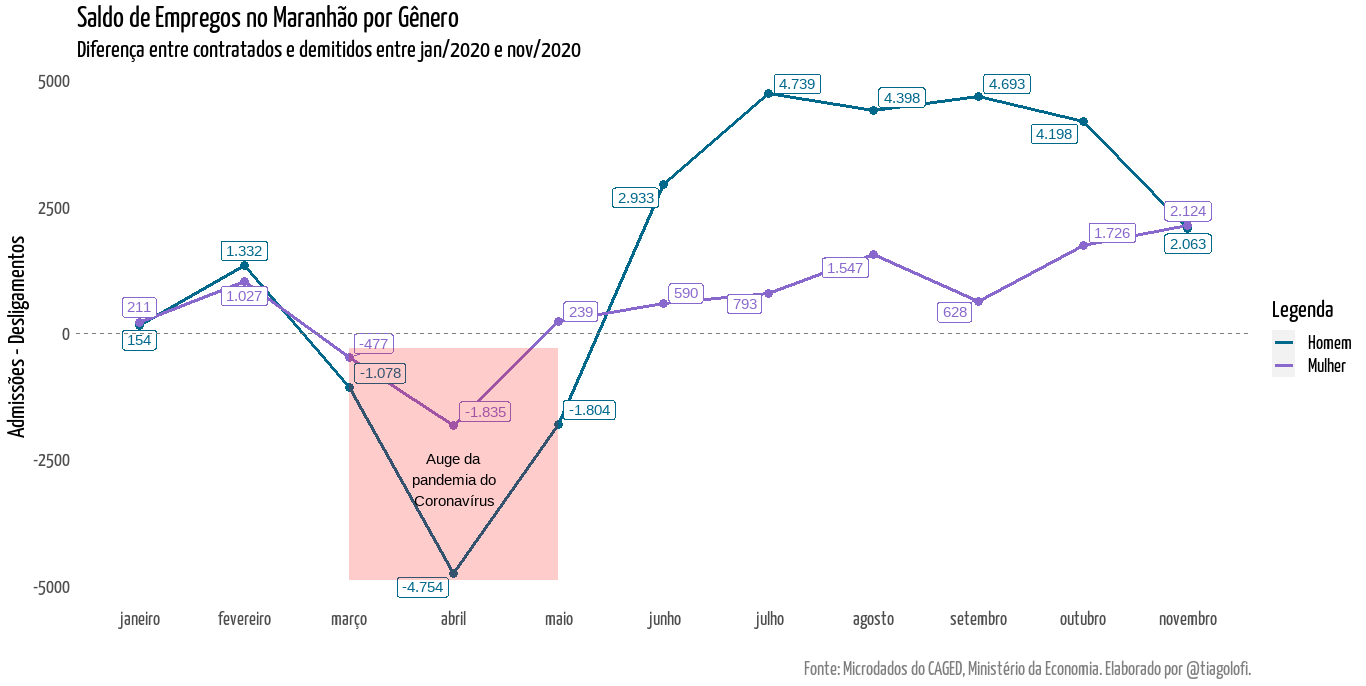
Interessante ver como a recuperação do emprego formal acontece e de que forma se setoriza, é possível notar que as perdas foram zeradas ainda em julho para os homens e para as mulheres isso ocorreu no mês seguinte, em agosto. (Essa quebra estrutural é uma dificuldade quando se trabalha com modelagem de séries temporais, fica aí o aviso). É possível notar que em novembro começa haver uma desaceleração na geração de empregos masculinos, já é um indício de retorno ao comportamento “normal” de criação e destruição de empregos.
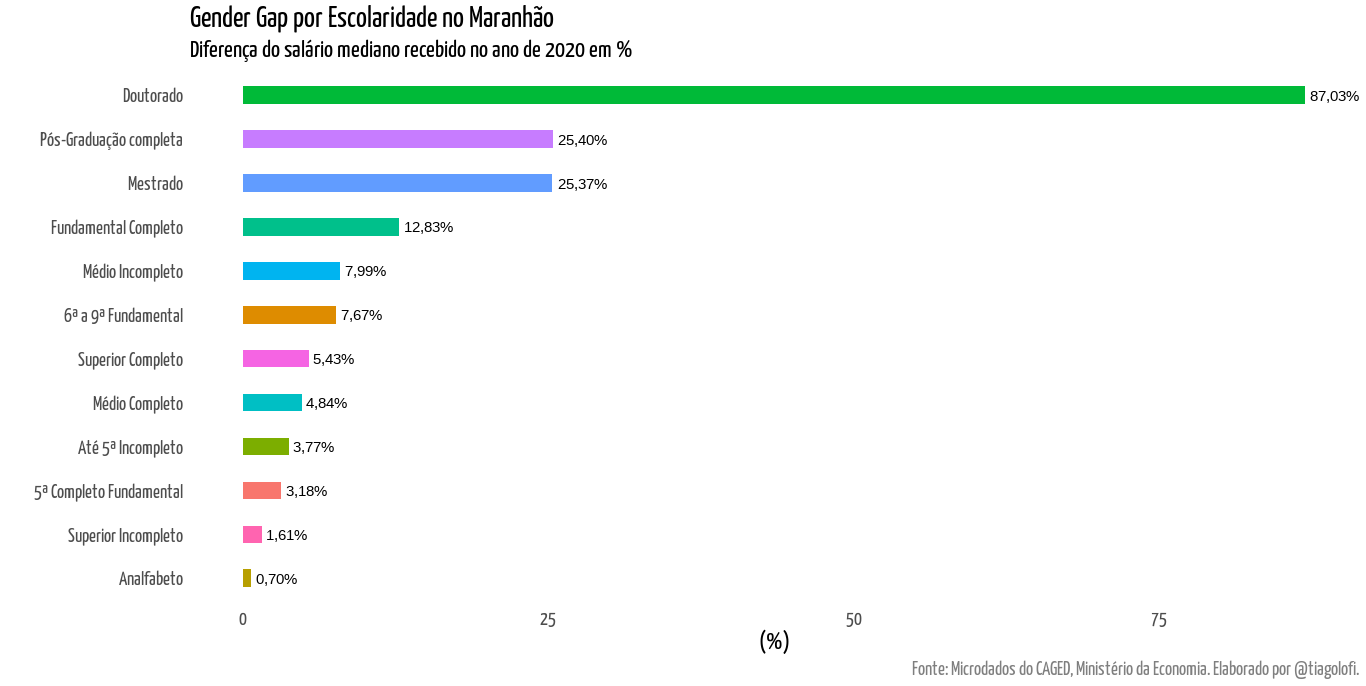
O segundo gráfico representa o gender gap por grau de instrução. Ou seja, a diferença de salário em termos percentuais considerando a divisão por gênero. Aqui optei pela mediana dos salários, a fim de evitar distorções causadas pelos super-salários que são recorrentes nessa base. Os dados mostram que, em 2020, para os trabalhadores formais, aqueles que eram homens e possuíam um doutorado receberam 87% a mais do que uma mulher que também possuía doutorado. Não é necessário alarde (ou é?), é preciso ponderar se esse diferencial de salário está sendo afetado por outra variável, por exemplo, o tipo de ocupação.
